![]()
![]()
![]()
![]()
An optimized implementation of the ORB-SLAM3 visual SLAM system, designed for embedded edge computing platforms.
This project addresses the high computational latency of visual feature extraction on mobile processors by implementing a Hybrid CPU-GPU Architecture.
⚡ Key Features & Optimizations
1. CUDA Accelerated ORB Extraction (GPU)
- Replaced the sequential descriptor extraction with a massive parallel CUDA Kernel.
- Utilizes Constant Memory for ORB patterns to minimize global memory latency.
- Achieves ~5x speedup in the descriptor calculation stage (from 23ms to 4ms).
2. Grid-Based Feature Distribution (CPU)
- Replaced the recursive QuadTree algorithm (standard in ORB-SLAM3) with a linear Grid-based filtering approach.
- Ensures uniform feature distribution with O(N) complexity.
- Reduces CPU overhead and branch mispredictions.
3. Optimized Memory Management
- Implemented Static Memory Pooling on the GPU to avoid
cudaMallocoverhead per frame. - Zero-copy data transfer where applicable (Unified Memory architecture).
Screenshots:
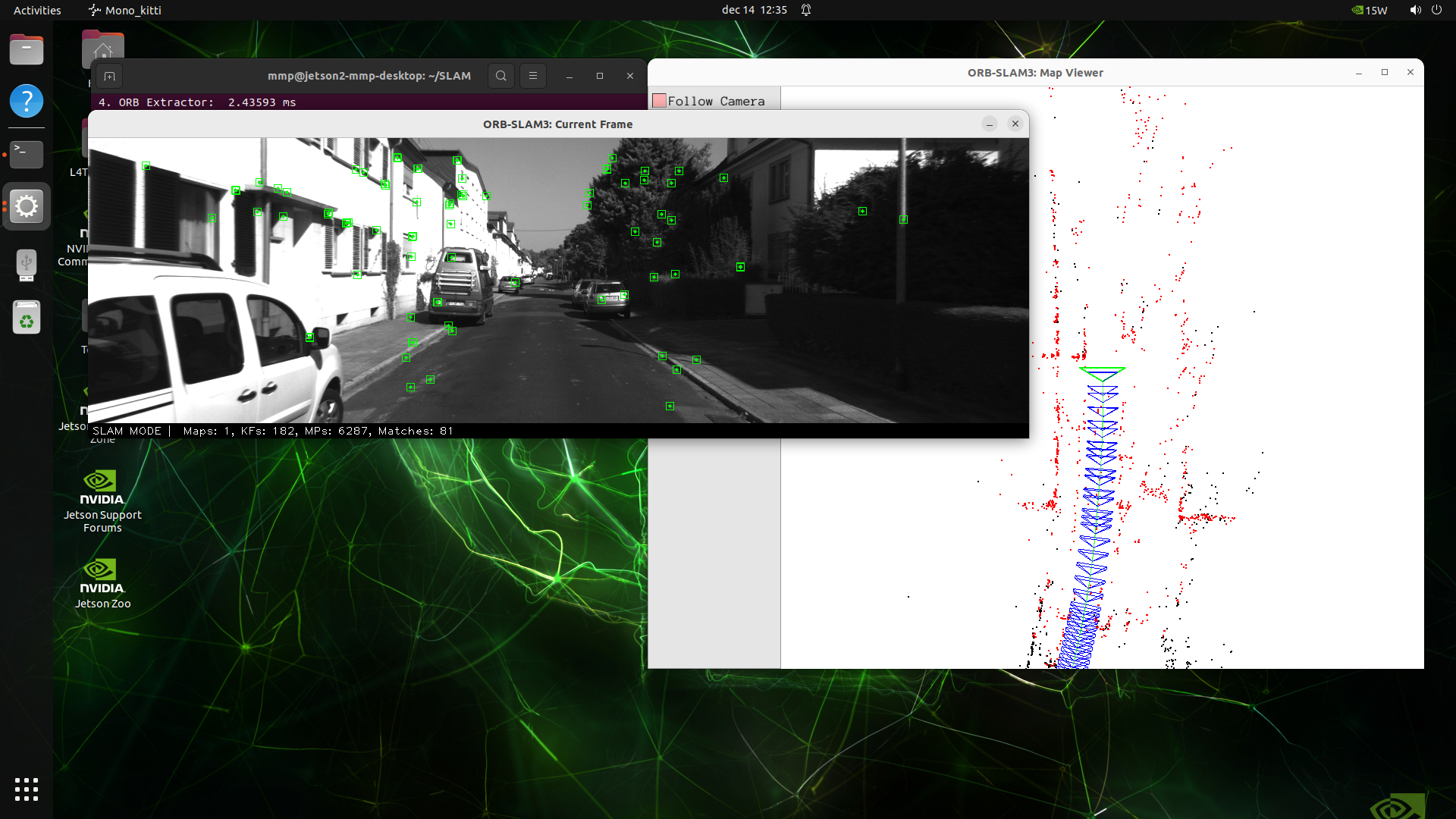
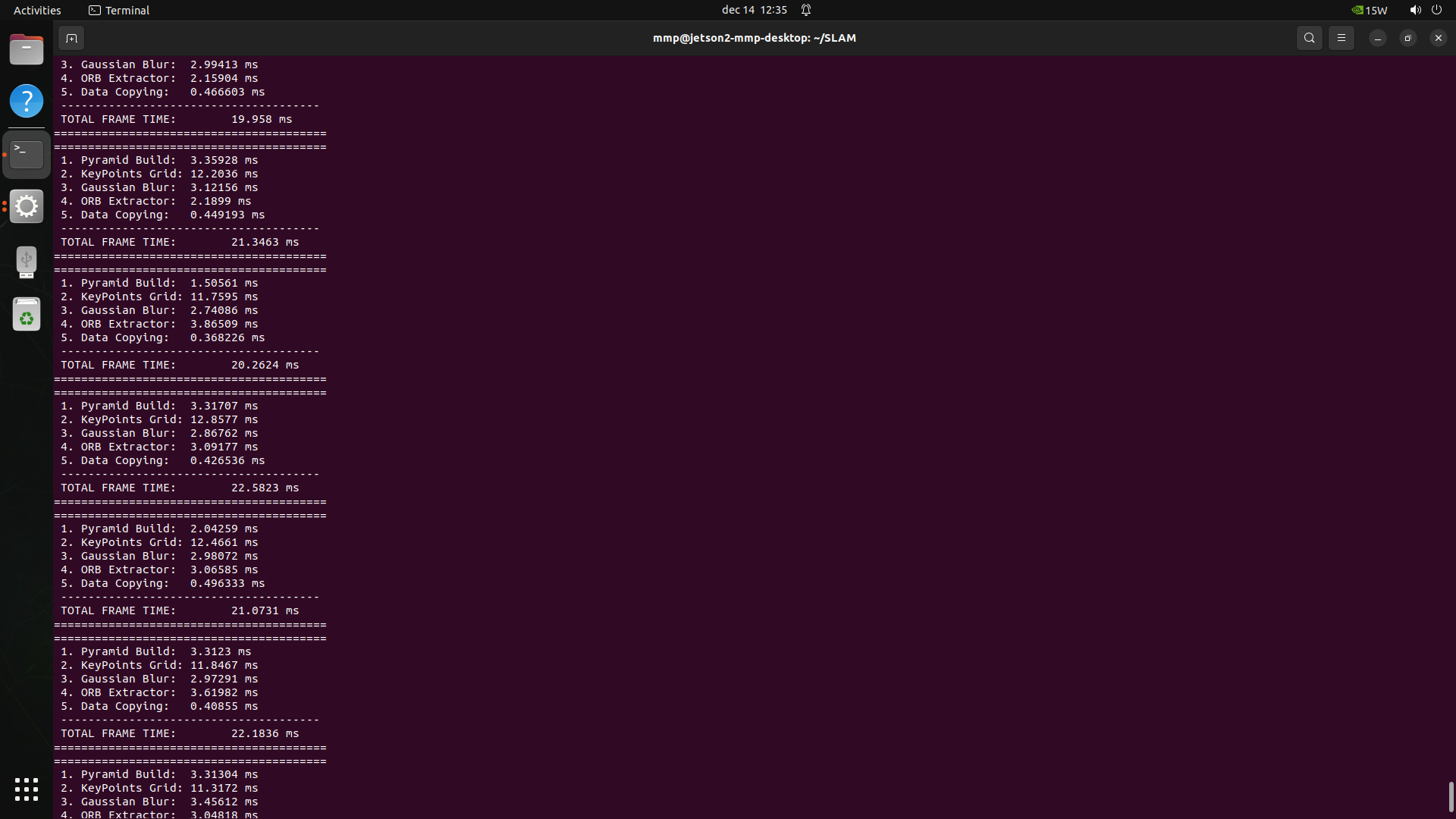
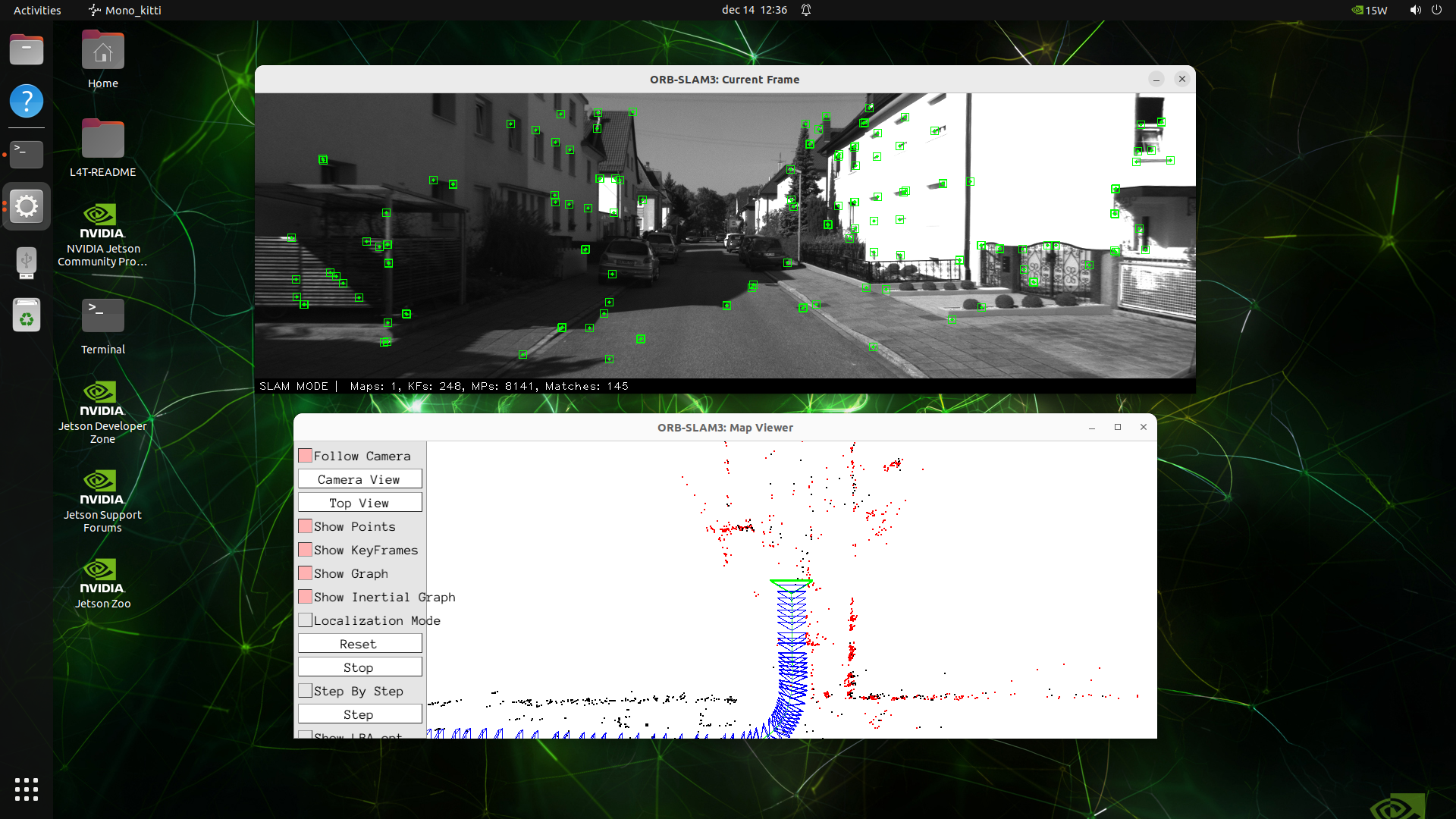
🤝 Acknowledgements
This project is based on ORB-SLAM3 by Carlos Campos, Richard Elvira, Juan J. Gómez Rodríguez, José M. M. Montiel and Juan D. Tardós.
Modifications by: Toth Antonio-Roberto
Technical University of Cluj-Napoca